Using Python to Build a Unified Multi-Chain Blockchain Data Harvesting Platform
Akshay Gupta
January 13, 2026
A unified approach to extracting blockchain data at scale—handling Solana-level throughput with Python.
The Challenge: Blockchain Data at Enterprise Scale
Here's a paradox: blockchain data is the most transparent in the world, yet one of the hardest to actually use at scale.
Every transaction, every block, every state change is recorded on an immutable ledger. Yet accessing this data reliably at enterprise scale remains a significant infrastructure challenge.
Organizations building analytics platforms, compliance systems, or blockchain intelligence tools face a common problem: how do you extract, transform, and load blockchain data across multiple networks without drowning in operational complexity?
This article explores how we built a unified data harvesting platform capable of handling everything from Ethereum to Solana-scale throughput—and why we chose Python to do it.
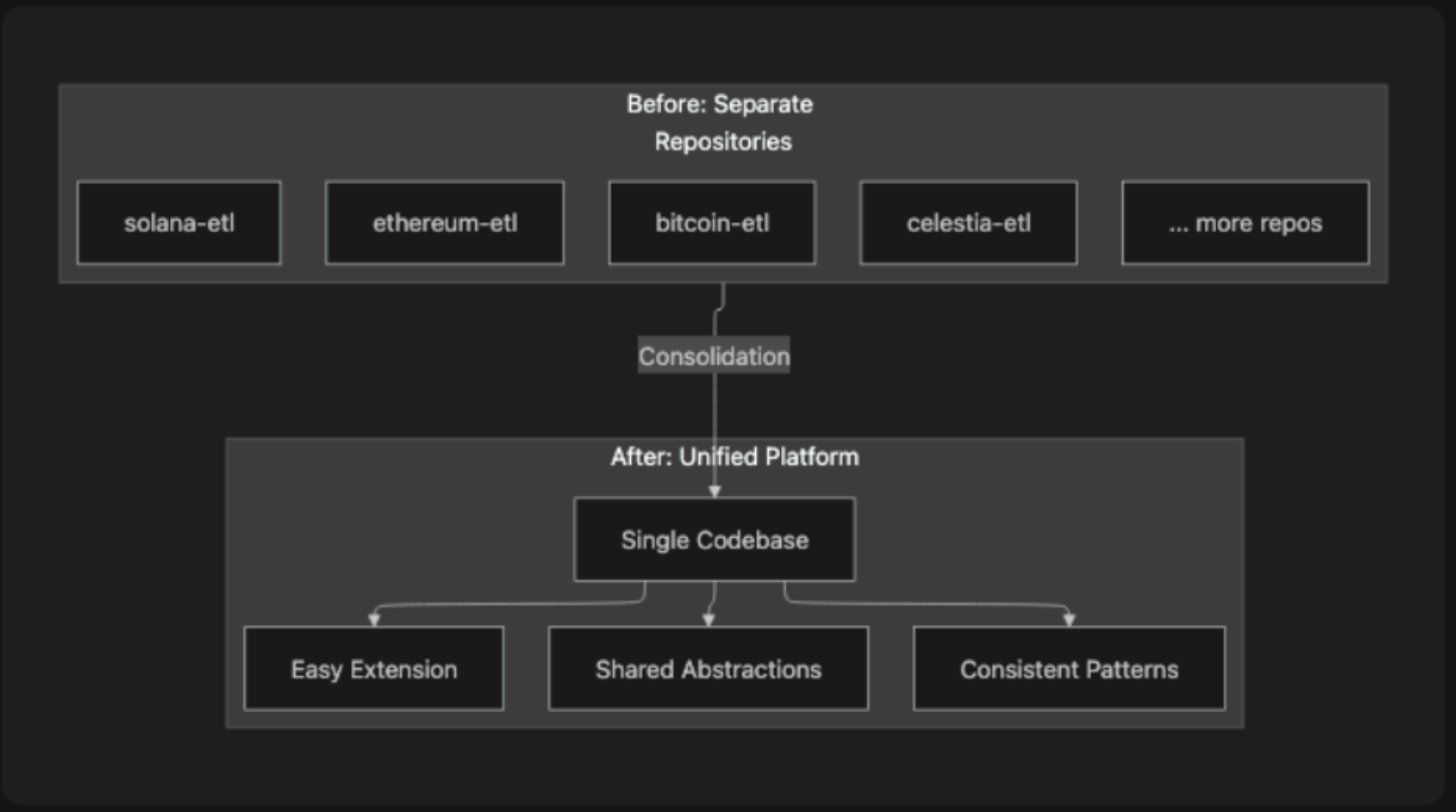
The Evolution: From Fragmented Tools to Unified Platform
The blockchain data extraction landscape has been shaped significantly by open-source projects like blockchain-etl. These pioneering tools demonstrated that blockchain data could be systematically extracted and made available for analysis at scale.
However, as organizations expand to support more blockchain networks, a pattern emerges: each chain requires its own tooling. Separate repositories for ethereum-etl, bitcoin-etl, solana-etl, and others. Each with its own patterns, configurations, and operational requirements.
The operational overhead compounds quickly:
Cognitive load: Each repository has different abstractions and patterns
Maintenance burden: Improvements must be implemented across multiple codebases
Onboarding complexity: Engineers must learn N different systems instead of one
Our approach: consolidate proven concepts into a unified architecture. One codebase. Shared abstractions. Consistent patterns across all supported chains.
The 3 Vs Challenge: Volume, Velocity, and Variety
Blockchain data presents a unique combination of big data challenges—the "3 Vs" of blockchain:
Volume: Modern blockchains generate massive amounts of data. A single day of Ethereum activity produces gigabytes of transaction data, logs, and traces. Historical backfills for mature chains require processing terabytes.
Velocity: High-throughput chains operate at unprecedented speeds. Solana produces blocks every 400 milliseconds with thousands of transactions per second. Data pipelines must keep pace or fall irretrievably behind.
Variety: Every blockchain architecture is different. EVM chains share common patterns, but variations exist in trace formats, receipt structures, and RPC behaviors. Non-EVM chains like Solana, Stellar, or Celestia have entirely different data models.
A solution that works for one chain but fails at another isn't a solution—it's a workaround.
Solana-Scale Engineering: Meeting the Throughput Challenge
Solana represents the ultimate stress test for blockchain data infrastructure. With thousands of transactions per second and 400ms block times, it exposes every weakness in naive approaches:
Sequential processing: Cannot keep pace with chain production
Memory-intensive approaches: Results in OOM errors during high-volume periods
Meeting this challenge required fundamental architectural decisions:
Pipelined processing: Overlap extraction, transformation, and export phases to eliminate blocking
Adaptive batching: Dynamically adjust batch sizes based on data density and RPC response characteristics
Backpressure handling: Gracefully throttle when downstream systems reach capacity
Memory-conscious design: Stream data through the pipeline rather than accumulating in memory
The principle: if the system handles Solana, it handles any blockchain.
The Power of Basics: Problem-Solving Over Fancy Tooling
High-throughput data challenges often lead teams down a familiar path—specialized frameworks, exotic dependencies, or exploring other languages. We took a different approach: understand the problem deeply, then solve it with fundamentals.
The bottleneck in blockchain data extraction isn't CPU-bound computation—it's I/O. Network calls to RPC nodes, disk writes, downstream system latency. Once we understood this, the path forward became clear.
The technical approach:
async / await: Concurrent RPC calls without thread overhead
ProcessPoolExecutor: CPU-bound transformation work with true parallelism
threading: Background I/O operations that don't block the event loop
No exotic frameworks. Minimal dependencies. Standard library primitives, used correctly.
The result: Solana-scale throughput with a codebase that remains readable, maintainable, and accessible to any developer. Good architecture beats complexity every time.
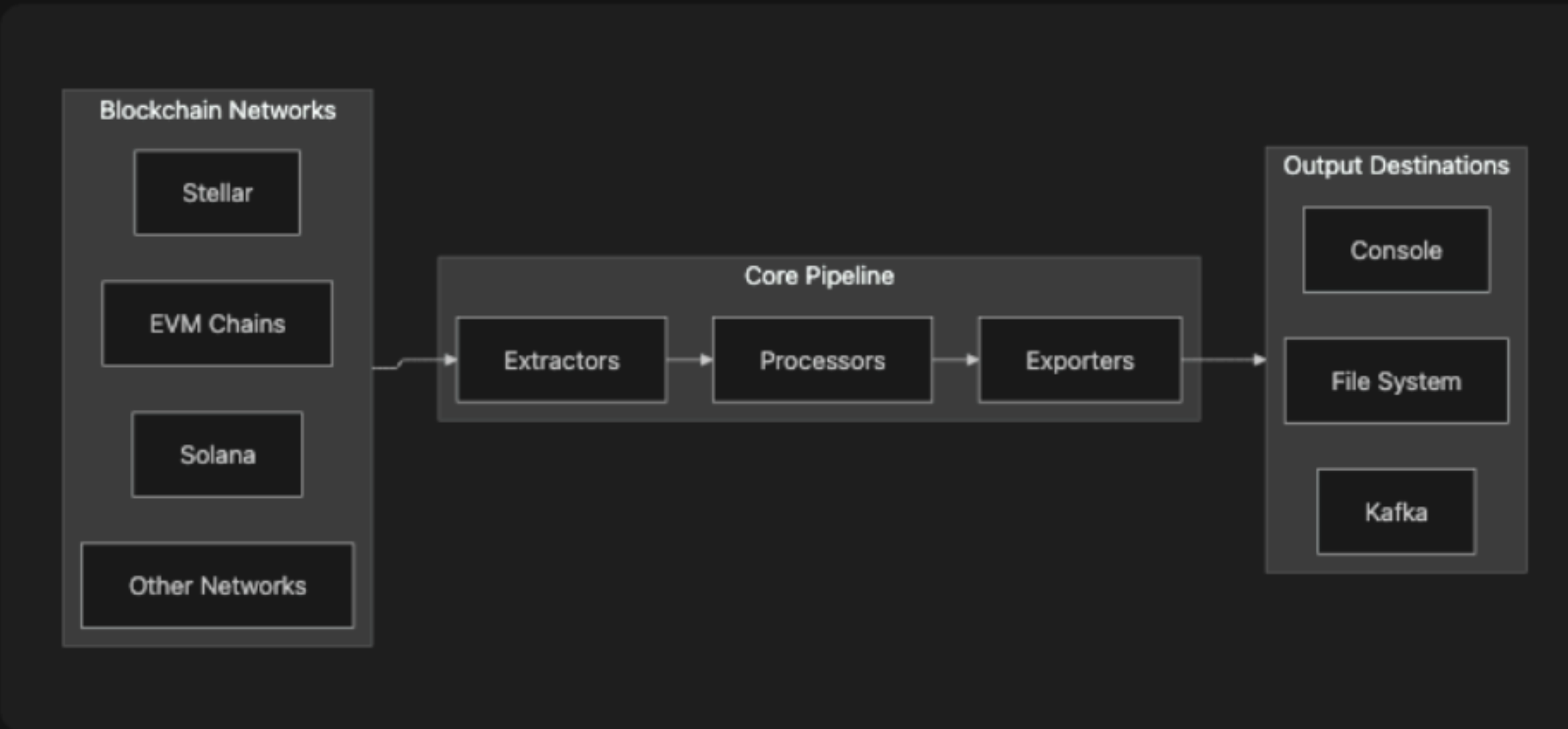
Architecture: Simplicity as a Feature
The platform follows a straightforward three-layer pattern:
Extractors manage RPC communication with blockchain nodes—batching requests, handling rate limits, implementing retry logic.
Processors transform raw blockchain data into structured formats, normalizing diverse RPC responses into consistent schemas.
Exporters deliver processed data to various destinations: file systems for batch workloads, Kafka for streaming pipelines, cloud storage for data lake integration.
Each layer maintains clean interfaces. Adding blockchain support means implementing an Extractor and Processor. Adding output destinations means implementing an Exporter. The core pipeline remains unchanged.
High-throughput L1s: Solana with its unique account model and transaction structure
Alternative networks: Stellar, Celestia, Ripple, TON, Zilliqa, Aleo
Rapid Expansion: Adding a new blockchain to our platform is now measured in days, not weeks. The shared abstractions mean engineers focus only on chain-specific logic; the infrastructure, reliability patterns, and output integrations come for free. The only external dependency? Access to the blockchain node itself.
The unified architecture ensures operational knowledge transfers across chains. Understanding how the platform handles one chain provides 80% of the knowledge needed for any other chain.
Key Capabilities
Real-time streaming: Follow the chain tip with configurable lag, processing blocks as they're produced. Automatic sync tracking enables seamless resume after interruptions.
Historical extraction: Backfill any date range or block range. Parallel processing handles large historical datasets efficiently.
Flexible output: Same data, multiple destinations. Local files for development, Kafka for production streaming, cloud storage for data lake integration.
Pipelined processing: Advanced streaming architecture overlaps extraction, processing, and export for 23x throughput improvements on high-frequency chains.
Reliability at Scale
Distributed systems fail. RPC nodes timeout. Networks experience issues. The question isn't whether failures occur—it's how the system responds.
Automatic retry with exponential backoff: Transient failures resolve without manual intervention.
Progress tracking and resume: Long-running extractions can be interrupted and resumed without data loss or duplication.
Atomic batch semantics: Batches succeed completely or retry entirely. No partial state to debug.
Graceful degradation: Under RPC pressure, the system throttles rather than crashes, catching up when conditions improve.
Key Takeaways
Understand the problem first — The bottleneck is I/O, not CPU. This shapes architectural decisions.
Basics beat complexity — async/await, process pools, threading. No exotic frameworks required.
Unify, don't multiply — One codebase > N repositories for operational efficiency.
Design for the hardest case — If it handles Solana, it handles any blockchain.
Conclusion: Infrastructure for the Multi-Chain Future
The blockchain ecosystem is evolving toward a multi-chain world where value and activity flow across dozens of networks. Data infrastructure must handle this diversity without proportional complexity.
Our platform delivers enterprise-grade blockchain data extraction without the complexity typically associated with high-throughput systems. A unified codebase supports diverse blockchain architectures with consistent operational patterns—enabling rapid expansion as the ecosystem evolves.
The multi-chain future requires multi-chain infrastructure. We built it. Interested in learning more about our blockchain data infrastructure? Get in touch—we'd love to discuss how we're solving these challenges.
This article describes high-level architectural approaches to blockchain data extraction. Specific implementation details remain proprietary.
 Compass
Compass Tracker
Tracker KYBB
KYBB Institute
Institute